

Kafka 简介
目录
最近接触到了kafka和zookeeper,顺便把一些知识点记录一下备忘……
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
简介
Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
为什么我们要使用消息系统呢?
- 解耦:消息系统在数据处理过程中间插入了一个隐含的接口层,两边的处理过程都要实现这一接口。这允许我们独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 扩展:消息队列解耦了处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
- 易恢复:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
- 异步:消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Kafka 架构
概念
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker;
- Producer:负责发布消息到Kafka broker;
- Consumer:消息消费者,向Kafka broker读取消息的客户端;
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group);
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处);
- Partition:Parition是物理上的概念,每个Topic包含一个或多个Partition;
- Segment:Partition物理上由多个segment组成;
- Offset:每个Partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。Partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息;
拓扑
一个kafka集群一般由以下部分构成:
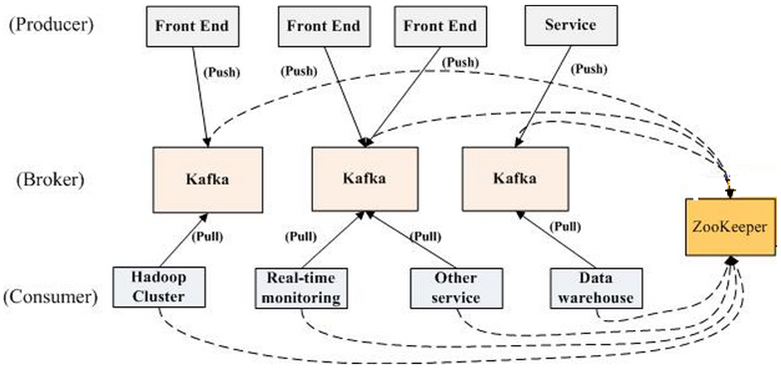
- 若干个Producer:产生消息数据,push到broker;
- 若干个Broker:Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高;
- 若干个Consumer:从broker pull消息,对消息数据进行处理;
- 若干个Consumer Group:一般情况下,同一个group的consumer不会重复处理数据;
- 一个zookeeper集群:Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance;
物理结构
在逻辑上,我们可以认为topic是一个queue,每个producer指定了topic之后就将其产生的消息push到相应的queue。
在物理上,为了使得Kafka的吞吐率可以线性提高,kafka把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
配置文件 server.properties 中主要涉及的参数有:
- log.dirs=/data/kafka:数据文件存储根目录
- num.partitions=1:默认的partitions数量
在单机环境(只有一个broker),创建一个名为 test 的 topic,partitions=2:
# 首先下载 kafka $ tar -xzf kafka_2.11-0.9.0.0.tgz $ cd kafka_2.11-0.9.0.0 # kafka 的运行需要依赖 zookeeper,下载的包内置了一个 zookeeper,我们可以直接启动 $ ./bin/zookeeper-server-start.sh config/zookeeper.properties # 启动 kafka $ ./bin/kafka-server-start.sh config/server.properties # 创建 topic $ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic test $ ./bin/kafka-topics.sh --list --zookeeper localhost:2181
这样,我们在 /data/kafka 目录下将可以看到:
drwxrwxr-x 2 jachua jachua 4.0K 5月 9 17:24 test-0 drwxrwxr-x 2 jachua jachua 4.0K 5月 9 17:24 test-1
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录。每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中,segment文件生命周期由服务端配置参数决定。
segment文件
segment文件由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件。
segment文件的命名,partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度。
# /data/kafka/test-0 -rw-rw-r-- 1 jachua jachua 10M 5月 9 17:24 00000000000000000000.index -rw-rw-r-- 1 jachua jachua 0 5月 9 17:24 00000000000000000000.log

索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
Pykafka
接下来我们可以很容易使用python的第三方库pykafka进行操作,另外也有一个同类的kafka库kafka-python,其对balance consumer的支持比较弱,具体的对比可以参考issue。
from pykafka import KafkaClient
client = KafkaClient(hosts="127.0.0.1:9092")
print client.topics
topic = client.topics['test']
with topic.get_sync_producer() as producer:
for i in range(4):
producer.produce('test message ' + str(i ** 2))from pykafka import KafkaClient
client = KafkaClient(hosts="127.0.0.1:9092")
print client.topics
topic = client.topics['test']
consumer = topic.get_simple_consumer()
for message in consumer:
if message is not None:
print message.offset, message.value参考:
评论