

Spark入门笔记
目录
最近在折腾Spark,第一次使用,把一些内容记录一下……
快速上手
首先,怎么也得在自己的机器上部署一个spark的开发环境来做测试,所以先从官方下载spark的包:
- 如果想自己编译安装,可以选择 Source Code;
- 如果自己已经配置过Hadoop环境,可以选择Pre-Built with user-provided Hadoop;
- 如果之前没有配置过Hadoop,直接选择Pre-Built for Hadoop 2.6 and later;
下载来的二进制包(懒得自己编译了。。。),解压后在 ./bin 目录下就可以运行spark了。由于我们主要以python进行开发,因此后续都将使用pyspark:
$ ./bin/pyspark
Spark 最主要的抽象是叫Resilient Distributed Dataset(RDD) 的弹性分布式集合。RDDs 可以使用 Hadoop InputFormats(例如 HDFS 文件)创建,也可以从其他的 RDDs 转换。对于RDDs,主要有两种类型的操作:
- Transformations:返回一个新的RDDs;
- Actions:返回一个结果;
最简单的一个spark应用:
from pyspark import SparkContext
logFile = "YOUR_SPARK_HOME/README.md" # Should be some file on your system
sc = SparkContext(appName="Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))然后我们使用 spark-submit 运行:
# 在本地环境中执行 $ ./bin/spark-submit --master 'local[*]' SimpleApp.py
基础知识
Spark Application
Spark applications run as independent sets of processes on a cluster, coordinated by the
SparkContextobject in your main program (called the driver program).
每个spark应用程序由一个driver program构成,它在集群上运行用户的mian 函数来执行各种各样的并行操作(parallel operations)。
Driver Program
处理我们spark应用程序中main函数,同时创建SparkContext。
Shared Variables
共享变量能被运行在并行计算中,默认情况下Spark 运行一个并行函数时,这个并行函数会作为一个任务集在不同的节点上运行,它会把函数里使用的每个变量都复制搬运到每个任务中。共享变量有两种类型:
- broadcast variables:用来在所有节点的内存中缓存一个值;
- accumulators:只能执行“添加(added)”操作;
Cluster Managers
在集群上面运行时,SparkContext可以连接到不同类型的集群管理器(cluster managers)。目前,spark支持下面三个类型:
- Standlone:spark内置的一个简单的集群管理器,因此即使我们不配置YARN或者Mesos,也可以很容易创建一个Spark集群;
- Hadoop YARN:Hadoop v2的一个资源管理器;
- Apache Mesos:一个通用的集群管理器,可以运行Hadoop MapReduce和服务应用;
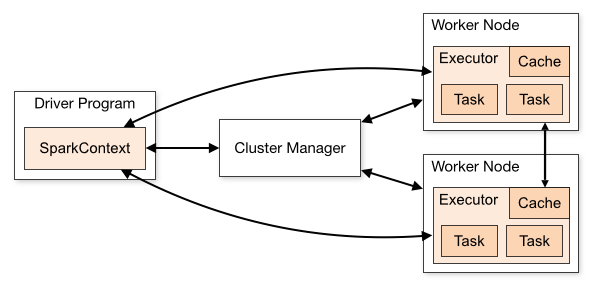 当SparkContext连接到Cluster Manager后,它就向集群中的节点申请executor,用来处理我们的任务和数据。
当SparkContext连接到Cluster Manager后,它就向集群中的节点申请executor,用来处理我们的任务和数据。
Executor
executor用来处理任务,同时也保存数据到内存或者磁盘中(参见:RDDs Persisitent)。其中有几个重要的参数:
- spark.dynamicAllocation.enabled:默认为false,如果设置为true,那个cluster manager会根据你的任务数量动态地调节executor的数量;测试中我们发现,应用刚启动,会分配尽可能多的executor,之后闲置的executor会被自动移除;
- spark.executor.cores:executor执行task时,能够并行执行的任务数量,这个需要根据cpu的vcore数量进行确定;
- spark.executor.memory:分配给每个executor的内存,根据自己作业的需求和节点机器的内存容量进行调节;
- –num-executors:指定分配executor的数量(如果超过了可分配的总量,则分配可用的所有executor),不过即使部分executor处于闲置状态,cluster manager也不会将其回收;
Spark编程
SparkContext & SparkConf
一般情况下,我们使用spark默认的配置参数,可以直接初始化一个SparkContext:
from pyspark import SparkContext sc = SparkContext(appName="test")
如果想要在代码中设置某个配置参数,我们可以通过SparkConf:
from pyspark import SparkContext, SparkConf
conf = SparkConf().set("spark.streaming.receiver.maxRate", 20000)
sc = SparkContext(appName="test", conf=conf)或者,我们也可以在spark-submit提交任务时指定某些参数:
$ ./bin/spark-submit --conf spark.streaming.receiver.maxRate=20000 test.py
注意:spark对于配置参数加载的优先级:代码设置 > –conf 指定> 配置文件 spark-defaluts.conf,如果我们需要详细看到哪些参数是如何配置的,我们可以在spark-submit时加入 –verbose 参数。
应用部署
spark-submit
我们一般采用spark-submit提交任务:
./bin/spark-submit \ --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application> \ [application-arguments]
- –master:
- 本地测试时,我们采用 –master local[*],其中 * 代表机器CPU核数,也就是启动的Thread数量;
- 如果spark集群对外开放,我们可以指定 –master spark://host:7077 (默认端口);
- 或者我们直接ssh到spark集群的master节点上进行运行,可以省略该参数;
- –deploy-mode:
- client:默认,以外部client的形式运行任务,这时候log直接输出到终端,如果我们ctrl + c 取消,那也将会终止任务的执行;
- cluster:将driver program运行在集群的某一个节点上,即使ctrl+c取消,任务也会继续执行(可以去Hadoop的资源管理器kill)
- –conf:以 key=value 的形式指定其他spark参数,具体可以查看文档;
此外,我们还可以通过直接运行spark-submit看到其他更多可设置的参数,如 num-executors, executor-cores 等等。
第三方依赖库
通常情况下,我们的应用中都会包含一些第三方的库,或者是我们的代码不止一个文件。这时,我们可以通过 –py-files 参数添加额外的代码文件:
# 将第三方库,多余的源码文件打包为zip $ zip -r library.zip third_lib/* other_codes/* # test.py 中有程序执行入口(main函数) $ ./bin/spark-submit --py-files library.zip test.py
Supervise
为了使我们的应用在异常退出(fails with non-zero exit code)能够自动重启,我们可以在spark-submit时加入 –supervise 参数。
AWS EMR
亚马逊AWS EMR服务中的Spark采用 YARN 作为Cluster Manager。因此,提交到EMR Spark的应用都运行在YARN中,每一个Spark executor也都运行在YARN container中。
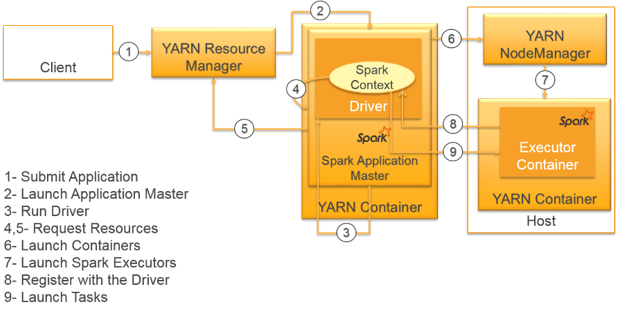
Cluster Mode
当我们spak-submit –deploy-mode cluster 时,driver program运行在Application Master 中:
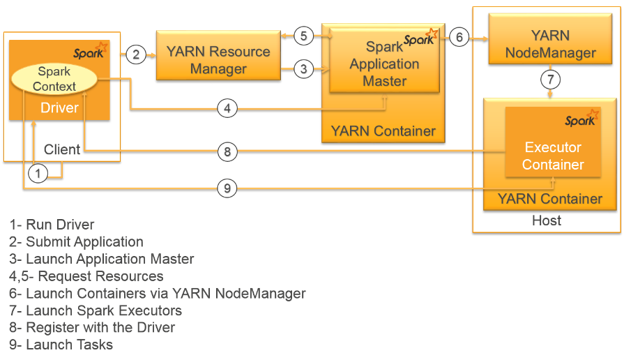
Client Mode
当我们spark-submit –deploy-mode client 时,driver program 并不会运行在Application Master内,而是运行在我们提交任务(spark-submit)的机器。
内存使用分析
在官方的文档中,我们留意到有两个参数:spark.driver.memory和spark.yarn.am.memory:
- spark.driver.memory:默认1G
Amount of memory to use for the driver process, i.e. where SparkContext is initialized. (e.g.
1g,2g).
Note: In client mode, this config must not be set through theSparkConfdirectly in your application, because the driver JVM has already started at that point. Instead, please set this through the--driver-memorycommand line option or in your default properties file.
- spark.yarn.am.memory:默认512M
Amount of memory to use for the YARN Application Master in client mode, in the same format as JVM memory strings (e.g. 512m, 2g). In cluster mode, use spark.driver.memory instead.
Use lower-case suffixes, e.g. k, m, g, t, and p, for kibi-, mebi-, gibi-, tebi-, and pebibytes, respectively.
参考:
评论