

Zookeeper
目录
Kafka的运行依赖于zookeeper,那么zookeeper这货究竟是啥……
简介
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
安装配置
从官方下载Zookeeper的二进制包,解压到本地即可直接运行:
$ wget http://mirror.bit.edu.cn/apache/zookeeper/stable/zookeeper-3.4.8.tar.gz $ tar -zxvf zookeeper-3.4.8.tar.gz $ cd zookeeper-3.4.8
配置文件在 conf/zoo.cfg,其中部分参数:
# The number of milliseconds of each tick tickTime=2000 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/tmp/zookeeper # the port at which the clients will connect clientPort=2181
- tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
- dataDir:Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
- clientPort:客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
然后我们就可以启动zookeeper了:
$ ./bin/zkServer.sh start $ ./bin/zkServer.sh status $ ./bin/zkServer.sh stop
集群
上面我们以standalone的形式启动了一台zookeeper服务器,但这样的部署方式并非高可用的。 虽然ZooKeeper是一个针对分布式系统的协调服务,但它本身也是一个分布式应用程序。为了实现高可用性,我们可以考虑以集群的方式进行部署:
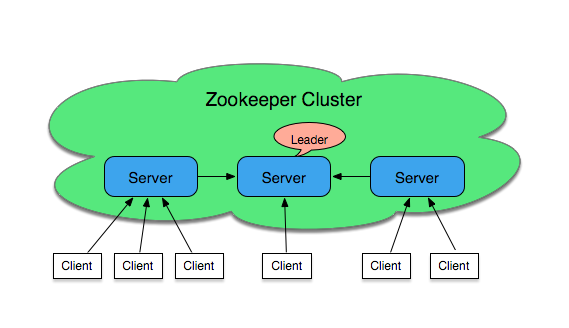
ZooKeeper 服务器的集合形成了一个 ZooKeeper 集合体(ensemble)。在任何给定的时间内,一个 ZooKeeper 客户端可连接到一个 ZooKeeper 服务器。每个 ZooKeeper 服务器都可以同时处理大量客户端连接。每个客户端定期发送 ping 到它所连接的 ZooKeeper 服务器,让服务器知道它处于活动和连接状态。被询问的 ZooKeeper 服务器通过 ping 确认进行响应,表示服务器也处于活动状态。如果客户端在指定时间内没有收到服务器的确认,那么客户端会连接到集合体中的另一台服务器,而且客户端会话会被透明地转移到新的 ZooKeeper 服务器。
配置
修改配置文件 conf/zoo.cfg:
# The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # zookeeper server server.1=192.168.211.1:2888:3888 server.2=192.168.211.2:2888:3888
- initLimit:Zookeeper 服务器集群中 Follower 服务器连接到 Leader 服务器,初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳时间(tickTime)的长度后表明连接失败。总的时间长度就是 10*2000=20 秒;
- syncLimit:标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 5*2000=10 秒;
- server.A=B:C:D
- A 是一个数字,表示这个是第几号服务器;
- B 是这个服务器的 ip 地址;
- C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
- D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
规模
当客户端请求读取特定 znode 的内容时,读取操作是在客户端所连接的服务器上进行的。因此,由于只涉及集合体中的一个服务器,所以读取是快速和可扩展的。
然而,为了成功完成写入操作,要求 ZooKeeper 集合体的严格意义上的多数节点都是可用的。在启动 ZooKeeper 服务时,集合体中的某个节点被选举为领导者。当客户端发出一个写入请求时,所连接的服务器会将请求传递给领导者。此领导者对集合体的所有节点发出相同的写入请求。如果严格意义上的多数节点(也被称为法定数量(quorum))成功响应该写入请求,那么写入请求被视为已成功完成。然后,一个成功的返回代码会返回给发起写入请求的客户端。
法定数量是通过严格意义上的多数节点来表示的。因此,节点数量应该是奇数的。而对于数据的写入,只有当写入法定数量的节点时,写入操作才是成功的。这意味着,随着在集合体中的节点数量的增加,写入性能会下降,因为必须将写入内容写入到更多的服务器中,并在更多服务器之间进行协调。
因此,在 ZooKeeper 集合体中,三、五或七是最典型的节点数量
数据模型
ZooKeeper 的数据模型类似于Unix文件系统,由 znodes 组成。可以将 znodes(ZooKeeper 数据节点)视为类似 UNIX 的传统系统中的文件,但它们可以有子节点。存储在 znode 中的数据的默认最大大小为 1 MB。
不过,即使 ZooKeeper 的层次结构看起来与文件系统相似,也不应该将它用作一个通用的文件系统。相反,应该只将它用作少量数据的存储机制,以便为分布式应用程序提供可靠性、可用性和协调。
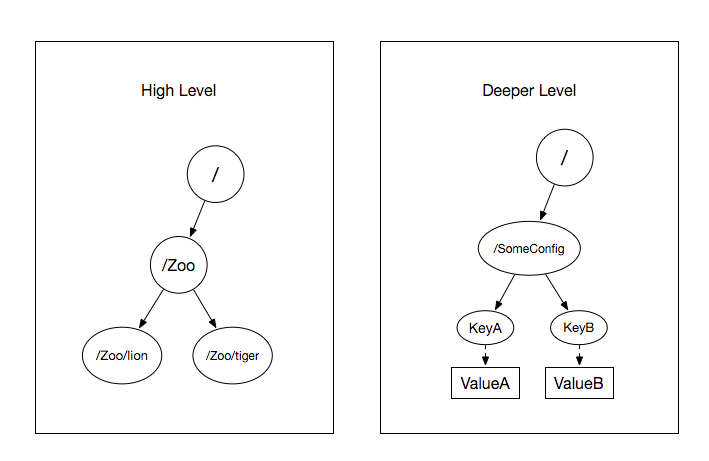 通过 zkCli.sh 我们可以查看zookeeper中存储的数据:
通过 zkCli.sh 我们可以查看zookeeper中存储的数据:
$ ./bin/zkCli.sh [zk: localhost:2181(CONNECTED) 0] help ZooKeeper -server host:port cmd args connect host:port get path [watch] ls path [watch] set path data [version] rmr path delquota [-n|-b] path quit printwatches on|off create [-s] [-e] path data acl stat path [watch] close ls2 path [watch] history listquota path setAcl path acl getAcl path sync path redo cmdno addauth scheme auth delete path [version] setquota -n|-b val path [zk: localhost:2181(CONNECTED) 1] ls / [test, zookeeper] [zk: localhost:2181(CONNECTED) 2] get /zookeeper/quota cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x0 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 0 [zk: localhost:2181(CONNECTED) 3] rmr /test
Zk in Kafka
说了这么多,我们现在来看看zookeeper在kakfa中的作用。我们知道Kafka的运行必须依赖于zookeeper,对于kafka的配置 config/server.properties:
############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=localhost:2181 # Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=6000 delete.topic.enable=true
其中,最关键的参数 zookeeper.connect,这里我们也可以指定某一个znode,比如:
zookeeper.connect=localhost:2181/kafka_test
那么所有相关的数据都是存储到 /kafka_test 这个 znode 下。
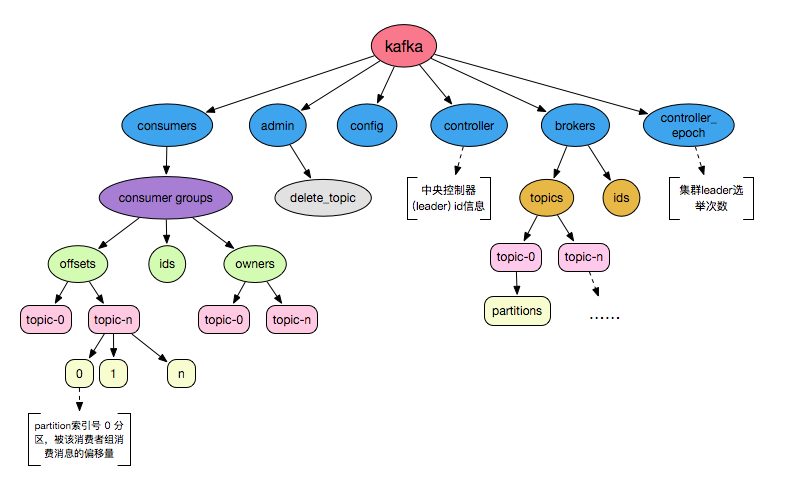
KafkaOffsetMonitor
对于kafka中的topics、consumer groups、offset等数据,为了方便查看,我们可以通过KafkaOffsetMonitor进行查看,具体详见github。
首先,下载kom的jar包,然后启动:
java -cp KafkaOffsetMonitor-assembly-0.2.1.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--offsetStorage kafka
--zk zk-server1,zk-server2 \
--port 8080 \
--refresh 10.seconds \
--retain 2.daysPykafka
参考官方文档,初始化 KafkaClient 时指定 zookeeper_hosts,然后就可以创建 balanced_consumers:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pykafka
def main():
client = pykafka.client.KafkaClient(zookeeper_hosts="localhost:2181/kafka_test")
print client.topics
topic = client.topics["test"]
consumer = topic.get_balanced_consumer(consumer_group="spark")
for msg in consumer:
print msg, msg.offset, msg.value
break
if __name__ == "__main__":
main()
评论